@Async는 어떤식으로 실행될까?
예제 코드
@Slf4j
@Service
@RequiredArgsConstructor
public class Producer {
private final EmailService emailService;
public void doSomething() {
emailService.send();
log.info(">>> doSomething");
}
}
@Slf4j
@Service
public class EmailService {
@Async
public void send() {
log.info(">>> 이메일 전송 시작");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info(">>> 이메일 전송 완료");
}
}이메일 발송은 1초의 작업 소요시간이 걸리는 외부 API 호출이라고 가정해보자.
일반적인 상황에서는 다음과 같은 순서로 로그가 출력될 것입니다.
1.이메일 전송 시작
2.이메일 전송 완료
3.doSomething
하지만 @Async를 이용해서 비동기 논블록킹으로 실행하면 다음과 같이 로그가 출력됩니다.

논블록킹이기 때문에 호출된 함수의 작업의 완료될 때 까지 블록킹 되지 않고 호출만 하고 바로 다음 로직을 실행합니다.
또한 비동기이기 때문에 작업의 결과를 기다릴 필요가 없습니다. (시간 일치 x)
로그를 보면 @Async 메서드를 실행하는 스레드는 main 스레드가 아닌, task-1이라는 별도의 스레드를 만들어서 진행했다.
그럼 이 스레드는 어디서 가져온거고 어떻게 관리된 녀석일까?
@Asyn는 AOP를 이용해서 실행될 것이기 떄문에, 부가기능을 실행하는 녀석의 정체를 알기 위해서 디버그 포인트를 찍어서 조사해본결과 AsyncExecutionAspectSupport 이란 녀석을 만났습니다.

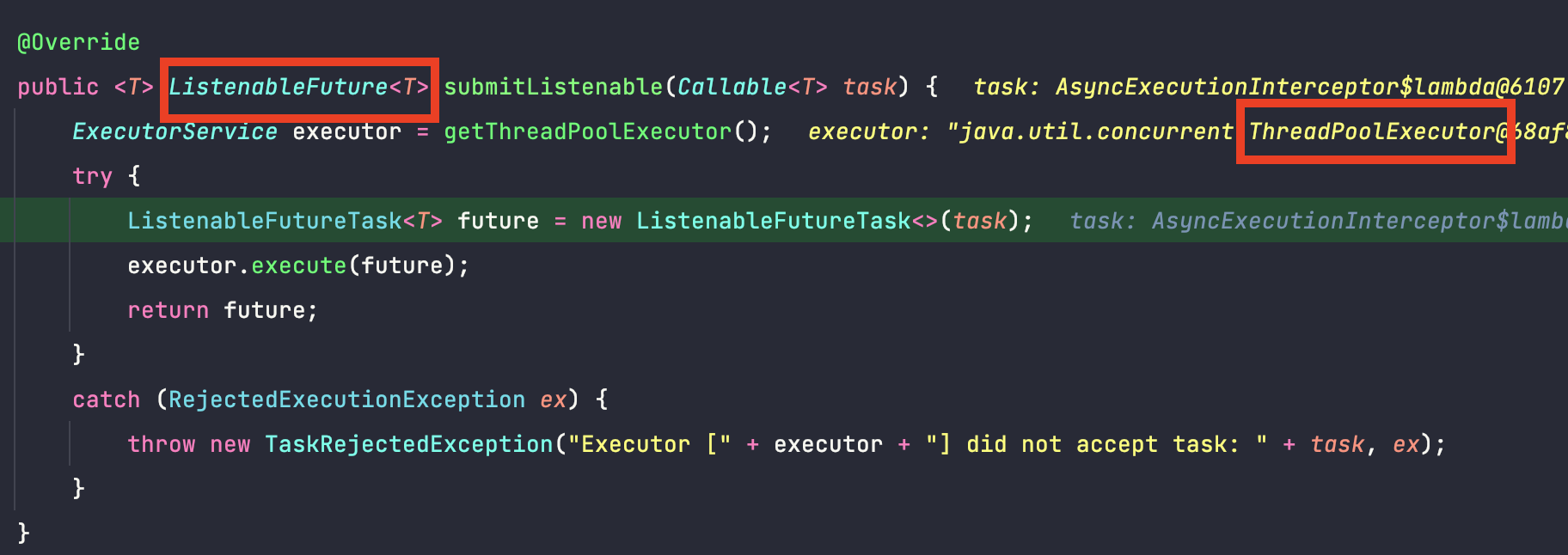
이 녀석을 조사하다보니 실제 작업을 수행하는 doSubmit을 발견했습니다. 이 메서드는 리턴타입을 void를 포함한 총 4가지의 케이스로 분리한 것을 확인할 수 있었습니다.

제가 작성한 코드에서는 리턴 타입이 없으므로 마지막 코드가 실행될 것입니다. 이부분을 디버그로 따라가서 조사해보겠습니다.
따라가보니 스레드를 관리하는 스레드풀을 ThreadPoolTaskExecutor를 이용하는 것을 확인할 수 있었습니다.



하지만 자료를 조사해본 결과 토비님이 발표한 2017스프링 캠프 발표 영상에서는 @Async는 기본적으로 스레드를 관리할 때 SimpleAsyncTaskExecutor를 이용해서 스레드를 생성한다고 하셨습니다.
SimpleAsyncTaskExecutor는 스레드를 재사용하지 않고, 매번 스레드를 새로 만들기 때문에 @Async를 이용하고 싶다면 ThreadPoolTaskExecutor으로 설정을 변경하라는 내용이 있었습니다.
실제로 SimpleAsyncTaskExecutor를 확인해본 결과 스레드를 재사용하지 않고, 매번 생성한다는 문구가 있었습니다.

음.. 그렇다면 기본 설정이 SimpleAsyncTaskExecutor에서 ThreadPoolTaskExecutor로 언제 변경된 것일까?
자료를 검색해봤지만, @Async는 SimpleAsyncTaskExecutor를 이용한다는 얘기만 있었고, 관련 내용을 찾을 수 없었습니다. 혹시라도 언제 변경된 것인지 아시는 분은 공유 해주시면 감사하겠습니다.
그럼 혹시 내가 잘못 캐치하고있는 걸까? 혹시 케이스마다 다를 수도 있나 싶어서 확인해보니 ListenableFuture, CompletableFuture 역시 동일하게 ThreadPoolExecutor를 사용하는 것을 확인할 수 있었습니다.
그렇다면 이번엔 ThreadPoolTaskExecutor에 설정을 추가하고 void에서 Future로 리턴 타입을 변경해보겠습니다.
@Configuration
public class ThreadPoolConfig {
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
final ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(30);
executor.setMaxPoolSize(30);
executor.setQueueCapacity(60);
executor.setThreadNamePrefix("woody-");
executor.initialize();
return executor;
}
}

get메서드는 응답값이 올 떄 까지 리소스를 점유합니다. 즉 블록킹이 되기때문에 아까와는 달리 doSomething 로그는 마지막에 출력됩니다. 또한 로그를 자세히 보면 비동기로 실행한 스레드 이름에 직접 설정한 prefix가 붙은걸 확인할 수 있습니다.

위와 같이 비동기 논블록킹으로 메서드를 실행하고 바로 블록킹으로 응답값을 기다리면, 비동기로 처리할 이유가 없어보인다. 오히려 스레드를 낭비하기 떄문에 좋아보이지 않습니다.
그럼 이번에는 ListenableFuture을 이용해서 콜백을 전달하고, 논블록킹으로 실행해보겠습니다.
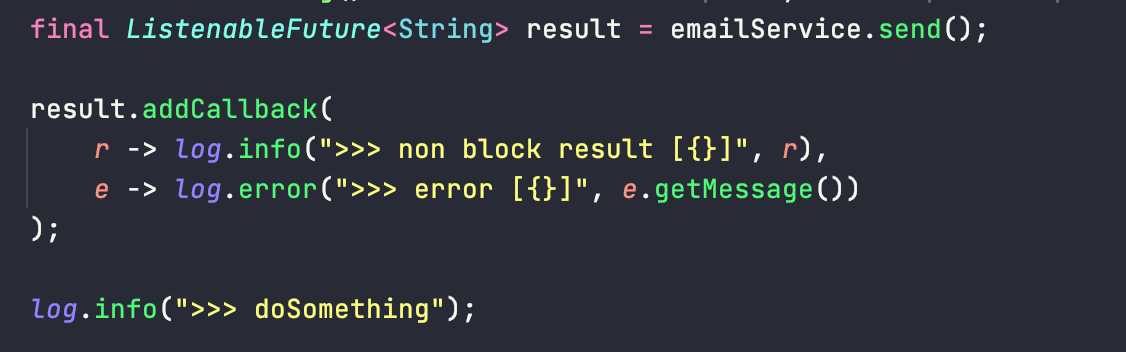
아까와는 달리 결과 값이 나올 때 까지 기다리지 않고, 결과가 나오면 콜백을 실행합니다.
즉 논블록킹으로 doSomthing을 실행하다가, 호출한 함수에서 응답값이 나오면 알아서 콜백을 실행합니다.

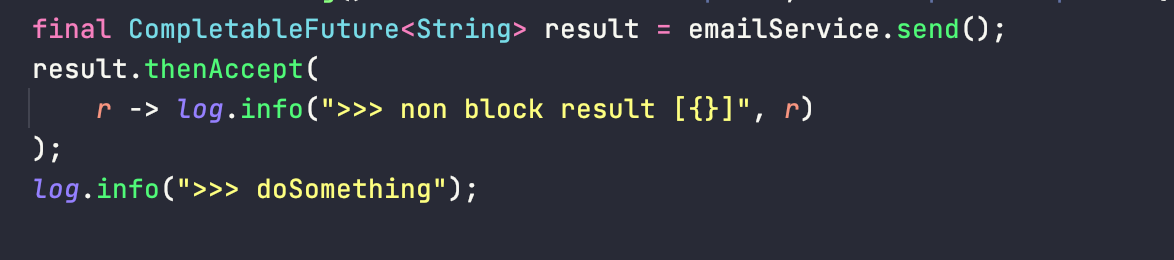
마지막 CompletableFuture를 사용한 케이스입니다.
CompletableFuture는 자바 8에서 등장한 것인데, 아직 깊게 공부해보지 않았지만 다음과 같이 논블록킹으로 실행 가능합니다.

마지막으로 아까 스레드 풀의 최대 스레드의 개수를 30으로 설정해놨는데, 실제로 스레드가 최대 30개 까지만 생성하는지 확인해 보았습니다. executor.setMaxPoolSize(30)
for (int i = 0; i < 60; i++) {
emailService.send();
}
log.info(">>> doSomething");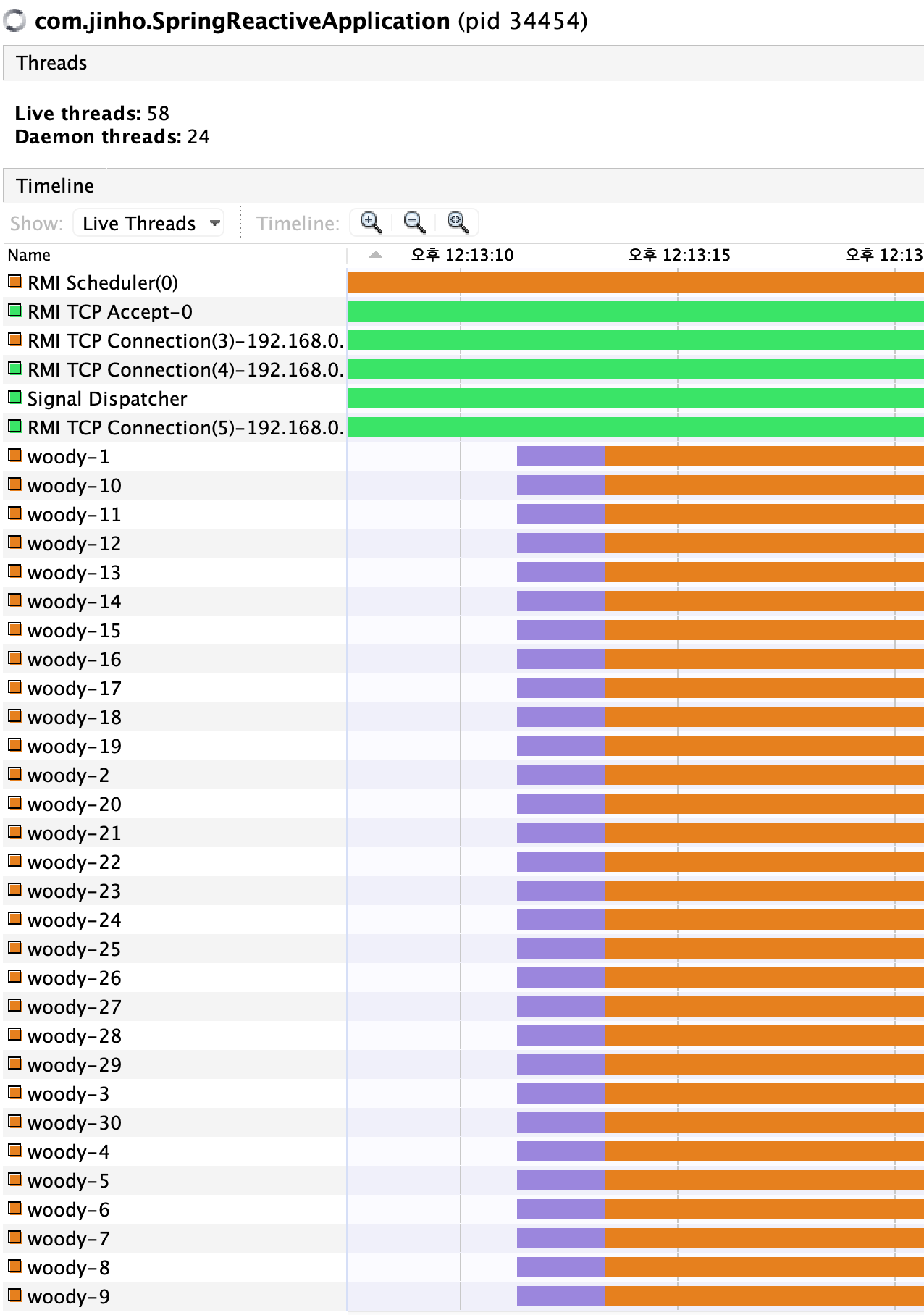
확인 결과 최대 30개의 스레드만 생성해서 작업을 수행하는 것을 확인할 수 있었습니다.
정리
1. @Async는 AOP를 통해 AsyncExecutionAspectSupport에 의해 실행됩니다.
2. 기존에 @Async를 이용하면 SimpleAsyncTaskExecutor을 이용해서 스레드를 재사용하지 않고 매번 만들었는데, 이제 ThreadPoolTaskExecutor를 이용해서 스레드를 관리합니다.
3. 비동기로 실행한 뒤 특정한 이유가 있가 있지 않는한, 블록킹으로 결과를 응답 받지 말자. 비동기로 처리한 이유가 없어지고 오히려 스레드를 낭비한다.
Reference
https://brunch.co.kr/@springboot/401
'Spring' 카테고리의 다른 글
| Transactional REQUIRES_NEW에 대한 오해 (7) | 2021.12.21 |
|---|---|
| Log4j 보안 이슈와 스프링 부트와의 상관 관계 (0) | 2021.12.11 |
| Spring AOP self-invocation이 발생하는 이유와 @Transaction 사용시 주의사항 (0) | 2021.08.11 |
| EventLister를 활용한 느슨한 결합 및 이벤트 처리. (0) | 2021.07.21 |
| ResponseEntity는 왜 사용하는 것이며 @RestControllerAdvice는 무엇일까. (2) | 2021.05.02 |