HashMap은 어떻게 동작할까? + 자바8에서의 변화
- hashCode의 특징
- HashMap의 내부 구조
- HashMap이 식별자를 구별하는 방법
- Java8에서의 HashMap의 변화
자바에서 가장 많이 사용하는 자료 구조 중 하나인 HashMap은 어떻게 동작할까?
우선 HashMap을 이해하려면 hashCode랑 equals의 개념을 먼저 알고있어야합니다.
(이 글에서는 다루진 않습니다)
이펙티브 자바 Item11에서는 "equals를 재정의하려거든 hashCode도 재정의하라"라는 내용이 있다.
HashMap의 동작 원리를 알게되면 왜 이런 얘기를 하는지 자연스럽게 이해할 수 있다.
우선 간단하게 hashCode의 특징을 짚고 넘어가자.
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
* <p>
* As much as is reasonably practical, the hashCode method defined
* by class {@code Object} does return distinct integers for
* distinct objects. (The hashCode may or may not be implemented
* as some function of an object's memory address at some point
* in time.)
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
@HotSpotIntrinsicCandidate
public native int hashCode();자바8 기준 Object클래스의 hashCode메서드에 대한 설명입니다.
해당 메서드는 오브젝트의 해시코드 값을 리턴하며, HashMap같은 해시 테이블을 사용할 때 이점을 제공해준다고 적혀있다.
설명을 더 보면 두 오브젝트가 equals를 통해 같다고 판별되면 hasCode또한 동일해야하고,
equals 메서드를 통해 다르다고 판별되더라도 hashCode가 꼭 달라야하는 것은 아니지만, hashCode가 다르면 해시 테이블을 사용할 때 성능상 이점이 있다는 등의 이야기가 나온다.
(참고로 서로 다른 객체는 동일한 해시코드를 가질 수 없다는라는 소문은 사실이 아닙니다.
hashCode의 범위는 정수형이므로 이는 비둘기 집의 원리로 증명 됩니다)
그렇다면 equals, hashCode는 HashMap을 사용할 때 구체적으로 언제 사용되며, 어떤 이점을 줄 수 있는시 알아보도록하자.
HashMap의 내부 구조

HashMap은 기본적으로 bucket 배열을 16으로 설정합니다. bucket이란 HashTable에 데이터를 담는 공간을 의미합니다.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
그리고 이 용량은 설정해 놓은 LOAD_FACTOR 기준에 다다르면 자동으로 2배씩 증가합니다.
용량을 적게 설정한 이유는 hashCode는 정수 범위의 값을 리턴하는데, 이 범위 전체의 배열을 만드려면 OutOfMemoryError가 발생할 수 있기 때문이다. (해시맵을 만들 때 마다 정수형 범위의 크기 배열을 만든다고 상상해보면...)
그럼 Collision은 어떻게 해결할까?
Separate chaining방식을 이용한다. 이는 버킷에 노드들이 위 사진과 같이 LinkedList로 연결되어있는 형태입니다.
위에 설명한 Node는 HashMap안에 내부 클래스로 존재합니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
HashMap이 식별자를 구별하는 과정
우선. Human객체를 생성하고 equals, hashCode를 오버라이드 해보자
public class Human {
private int age;
public Human(int age) {
this.age = age;
}
.. equals && hashCode Override
}
@Test
void same_identity() {
final Map<Human, Integer> map = new HashMap<>();
final Human human1 = new Human(10);
final Human human2 = new Human(10);
map.put(human1, 1);
map.put(human2, 2);
assertThat(map.size()).isEqualTo(1);
assertThat(map.get(human2)).isEqualTo(2);
}
우선 equals랑 hashCode를 재정의했다는 점에 주목하자.
그럼 human1, haman2의 내부 값이 같으므로 equals는 true를, hashCode는 동일한 값을 반환할 것이다.
우선 HashMap은 동일한 키 값을 중복 저장하지 않는다. 따라서 동일한 식별자로 put을 할 경우 최종 value가 저장 될 것이다.
따라서 동일한 식별자로 인식했다면, 최종적으로 값은 2가 저장된다. (size가 아닙니다)
그렇다면 두번째 put을 할 때 일어나는 내부 동작을 살펴보자.
human2가 human1이랑 동일한 식별자인지 어떻게 구별할까?
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// hash(key) : 해시 충돌을 최소화 하기 위한 추가 작업put은 putVal이라는 메서드를 호출하는데, key의 해시를 추가해서 인자로 전달합니다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // (1)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // (2)
tab[i] = newNode(hash, key, value, null);
else { // (3)
..
}
(1) map에 처음으로 값을 넣으면 동작한다
(2) 해당 인덱스 버킷에 처음 들어가는 값일 경우 해당 버킷에 Node를 추가한다.
(3) 해당 인덱스 버킷이 null이 아닐 경우 동작한다.
human1과 human2의 hash는 같은 값이므로 동일한 버킷 인덱스로 접근을 한다.
앞에서 map.put(human1, 1)을 했으므로 접근하는 인덱스의 버킷은 null이 아니므로 (3)로직이 동작한다.
자 그렇다면 이제 else 부분을 들어가보자.
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
...둘의 (hash가 같아야 하고) + (둘의 Key 참조가 같거나, equals가 같다면) 동일한 식별자라고 판단합니다.
다시말해 hashCode는 무조건 같아야한다. (조건문을 잘 해석해야합니다)
(여기서 hashCode와 equals를 오버라이딩 하는 이유를 알 수 있습니다)
따라서 위 조건에서는 true가 되므로 e = p;를 실행한다. (hashCode가 동일하고 equals가 true가 나왔으므로)
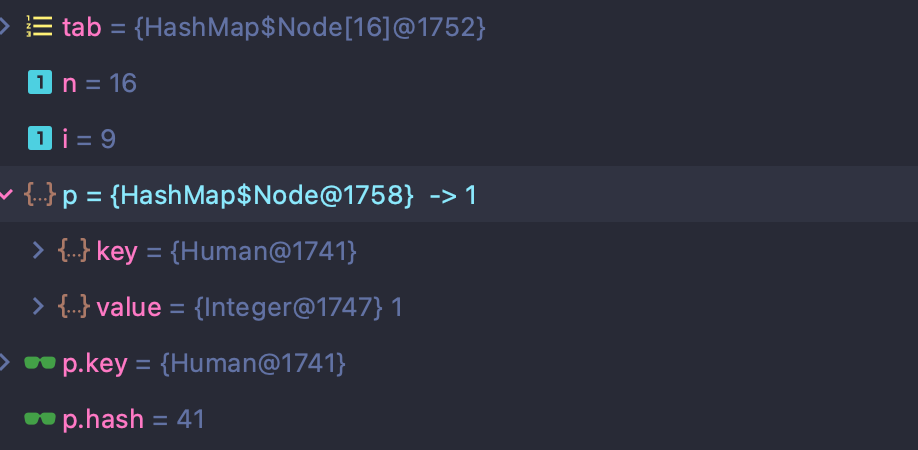
여기서 p는 위 코드로 올라가보면 (2)에서 초기화된 버킷의 Node입니다.
디버깅으로 확인해보면 p는 tabl[9(i)]의 Node인걸 확인할 수 있다. (i = 9)
이전에 put으로 넣은 값 1을 그대로 갖고있는 걸 확인할 수 있습니다.
이제 다음이 실행되는 로직은 심플합니다.
식별자에 해당하는 값을 새로운 값으로 변경하는 작업을 진행합니다.
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
최종적으로 결과 값이 2로 변경된 것을 확인할 수 있다.
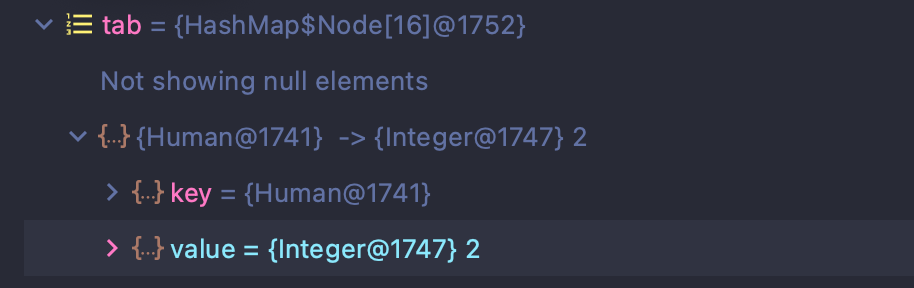
그렇다면 이번에 동일한 인덱스 버킷에 다른 식별자를 가진 여러 노드들이 있을 때는 어떤식으로 동작할까?
우선 다음과 같이 모든 Human객체의 hashCode를 동일하게 만들어서 동일한 인덱스 버킷에 저장될 수 있도록 해준다.
public class Human {
@Override
public int hashCode() {
return 1;
}
}값이 다르기 때문에 서로 식별자를 다르게 인식할 것이다. 즉 동일한 인덱스 버킷에 각각 다른 노드들로 저장됩니다.
마지막 map.put(human3, 2);를 할때 어떤식으로 동작하는지 확인해보자.
@Test
void t1() {
final Map<Human, Integer> map = new HashMap<>();
final Human human1 = new Human(10);
final Human human2 = new Human(20);
final Human human3 = new Human(30);
map.put(human1, 1);
map.put(human2, 2);
map.put(human3, 2);
assertThat(map.get(human1)).isEqualTo(1);
}
아까 실행했던 인덱스 버킷이 null이 아닐 경우 실행하는 로직입니다.
else {
Node<K,V> e; K k;
if (p.hash == hash && // (1)
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // (2)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { // (3)
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && // (4)
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}(1) 우리는 해시가 같지만, 값이 다르기 때문에 아까와 달리 실행되지 않는다.
(2) 해당 노드가 TreeNode 인스턴스인지 확인한다.
(3) 해당 버킷의 노드들을 순회하는 반복문.
(4) (1)과 같이 비교를 진행한다. 연결되 노드가 없을 떄 까지 (3) ~ (4)를 반복한다.
여기서는 첫번째 Node랑 식별자를 확인하는 과정에서 false가 나왔기 때문에 (3)을 실행한다..
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 순회가 끝났을 경우
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 임계값이 초과할 경우 트리화
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && // Node와 인자로받은 Key와 식별자가 같다면 순회를 멈춘다.
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}다음 포인터가 null이 나왔다는 것은, 해당 인덱스 버킷의 모든 노드들 중에 같은 식별자가 없다라는 뜻이므로
맨 끝 Node의 다음 포인터에 새로운 노드(human3, 3)를 추가하고 연결한다.
(그리고 만일 해시 버킷의 항목 수가 특정 임계값을 초과한다면 링크드 리스트에서 균형 트리로 전환한다)
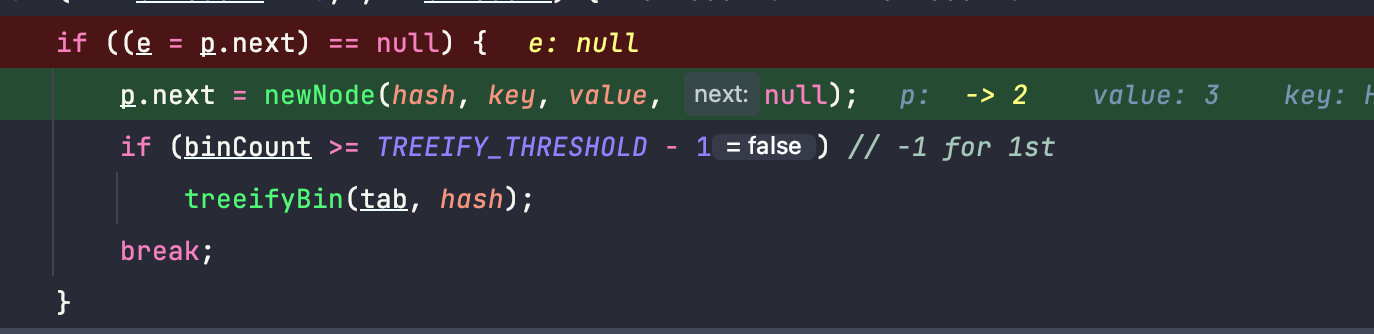
자 여기서 균형 트리로 변경한다고 했는데. 이부분이 자바 8에서 생긴 변화입니다.
자바7 까지는 노드를 링크드 리스트로만 연결했는데, 이럴 경우 최악의 경우 O(n)의 시간복잡도가 소요되지만,
균형 트리(red-black-tree)를 이용하면 O(log n)의 시간복잡도가 소요됩니다.
What's New in JDK8 글에 보면
- Performance Improvement for HashMaps with Key Collisions
라는 부분이 있습니다.
자세한 내용은 문서를 확인해보면 확인할 수 있습니다.
Improve the performance of java.util.HashMap under high hash-collision conditions by using balanced trees rather than linked lists to store map entries. Implement the same improvement in the LinkedHashMap class.
The principal idea is that once the number of items in a hash bucket grows beyond a certain threshold, that bucket will switch from using a linked list of entries to a balanced tree. In the case of high hash collisions, this will improve worst-case performance from O(n) to O(log n).
Reference
http://openjdk.java.net/jeps/180
https://www.oracle.com/java/technologies/javase/8-whats-new.html
'Java' 카테고리의 다른 글
| Generic Type Erasure는 어떻게 타입캐스팅을 하는건가요? (0) | 2021.12.07 |
|---|---|
| Java Parallel Programming 성능 테스트 및 고려사항 (JMH) (2) | 2021.07.25 |
| [Java] 새로운 날짜/시간 API Time소개, Date의 단점 (0) | 2021.02.10 |
| [Java] 함수형 인터페이스, 람다식 (0) | 2021.02.09 |